1. 问题描述
Link prediction是在知识图谱中预测实体之间的关系的任务,在查询扩展和语义关系预测中需要解决的,也是本论文致力于解决的。
在解决Link prediction, 其核心考虑因素在于:
link predictors should scale in a manageable way with respect to both the number of parameters and computational costs to be applicable in real-world scenarios.
同时需要考虑计算成本,还是考虑模型本身的预测性能,而参数数量是模型性能的一个指标。
之前方法的问题在于:
Previous work on link prediction has focused on shallow, fast models which can scale to large knowledge graphs. However, these models learn less expressive features than deep, multi-layer models which potentially limits performance.
简单来讲,之前的方法过于关注在大型知识图谱上进行快速的学习,这需要网络不太复杂。但是其架构学习到的特征不够丰富,性能不够强。
为了提高知识图谱上的预测性能,从而提高表现力,在不使用深层模型的前提下,只能提高embedding size,但是难以应用到大型知识图谱上。
换一种思路,使用深度模型,就可以减少embedding size,因为可以学到高层特征,但是在过往的模型中,深度模型中的使用的架构都是全连接层,因此会造成过拟合问题。
以上问题的一种解决办法是:
use parameter efficient, fast operators which can be composed into deep networks.
因此,自然而然,卷积的操作就被引入了,因为以下特点:
- parameter efficient
- fast to compute: highly optimised GPU implementations
本文提出来的模型:ConvE, a multi-layer convolutional network model for link prediction,这是一个基于卷积的多层架构。它的优点如下:
- highly parameter efficient: yielding the same performance as DistMult and R-GCN with 8x and 17x fewer parameters;
- particularly effective at modelling nodes with high indegree: common in highlyconnected, complex knowledge graphs such as Freebase and YAGO3;
2. 方法
2.1 1D vs 2D Convolutions
NLP任务中,多数使用1D卷积进行操作,即在文本的序列方向上进行卷积操作,本文使用2D卷积,不仅在文本序列方向进行操作,同时还在embedding的纵向上进行操作,这使用卷积操作捕捉到的交互信息更丰富。
这种操作的优点在于: increases the expressiveness of our model through additional points of interaction between embeddings.
这种操作如何理解?
当把1D的embedding 进行拼接时,你仍然需要得到1D的embedding,那么拼接的方法只能是在一维上,如下例:
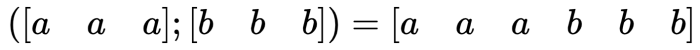
其中假如你的卷积核k=3, 那么能捕捉到的交互只有最临近的a和b, 除非你讲卷积核的尺寸增加,这样才能捕捉到更多的交互。
当换到2D时,由于是在二维的方向上进行拼接和堆叠,因此其方式可以有多种,因此当卷积进行操作时,可以捕捉的信息可以是左右方向的,也可以是上下方向的,如下图:
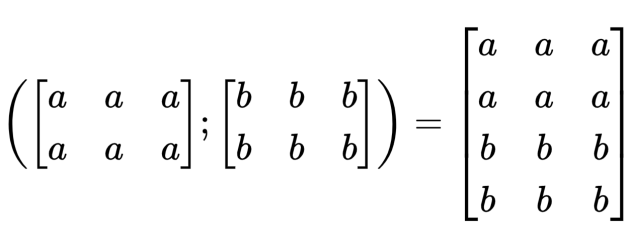
如果两种元素代表的意义不同, 那么交换它们的拼接方式还能进一步的提升交互次数:
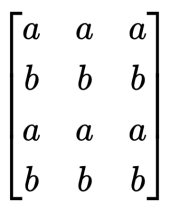
因此在2D条件下,捕捉到的交互信息数量是不单单与卷积核有关,而且还与矩阵的尺寸有关。
2.2 问题形式化
link prediction 可以认为是 a pointwise learning to rank problem。具体而言,对每个输入的三元组 triples: $x = (s, r, o)$, 目标是 learning a scoring function $\psi(x)$, 其结果正比于x为true的likelihood。
2.3 Neural Link Predictors
这个组件是干嘛的,深度学习中总有一些为了唬人提出的名词,其实这个predictors就是一个多层神经网络,包括:
- encoding component: 对 $x = (s, r, o)$, 该部分将subject和object映射为embeddings, $e_s$, $e_o$;
- scoring component: 使用 $\psi_r$ 对embeddings评分,即: $\psi(s, r, o) = \psi_r(e_s, e_o)$
一些经常使用的典型predictors如下:
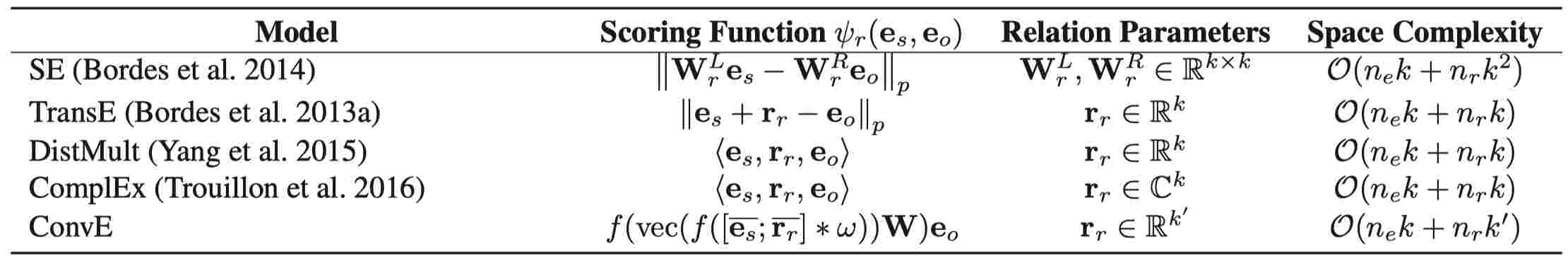
2.4 模型主要内容
2.4.1 Scoring function
scoring function定义如下:
$$
\psi_{r}\left(\mathbf{e}_s, \mathbf{e}_o\right)=f\left(\operatorname{vec}\left(f\left(\left[\overline{\mathbf{e}_s} ; \overline{\mathbf{r}_r}\right] \ast \omega\right)\right) \mathbf{W}\right) \mathbf{e}_o
$$
一些符号如下:
$\mathbf{e}_s, \mathbf{e}_o$ 分别代表头实体和尾实体的Embedding;
$\overline{\mathbf{e}_s}, \overline{\mathbf{r}_r}$ 分别代表Reshape后的头实体和关系向量,这种操作如下:如果 $\mathbf{e}_s, \mathbf{r}_r \in \mathbb{R}^k$, 那么 $\overline{\mathbf{e}_s}, \overline{\mathbf{r}_r} \in \mathbb{R}^{k_w \times k_h} $, 则 $k = k_w k_h$
$\omega$ 代表卷积核;
$\mathbf{W}$ 代表投影矩阵;
2.4.2 模型架构
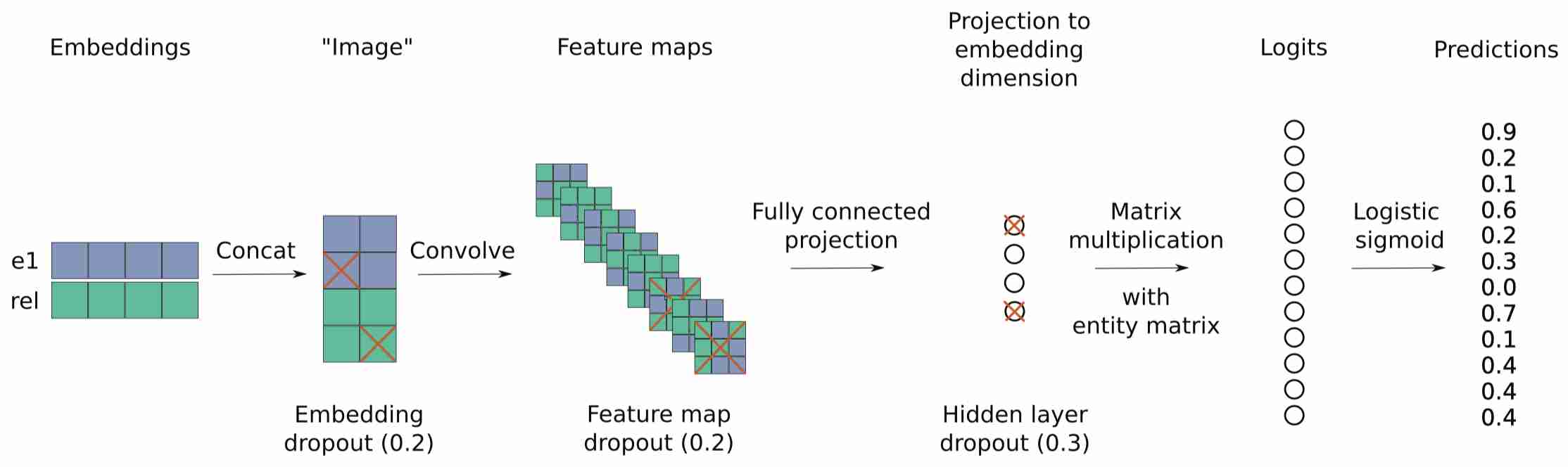
ConvE的整个训练过程如下.
- 先通过Embedding的方式分别获得头实体表示 $\mathbf{e}_s$ 和关系表示 $\mathbf{r}_r$ ;
- 将头实体和关系表示先
Concat起来, 然后将其Reshape到某一种尺寸, 此时头实体和关系的表示记为 $\left[ \overline{\mathbf{e}_s} ; \overline{\mathbf{r}_r} \right]$; - 接着利用卷积抽取Reshape后的二维向量, 也就是对头实体和关系的交互信息进行捕捉;
- 利用卷积(可以是任意数量的卷积核)抽取完信息后, 将所有的特征打平成一个一维向量;
- 通过投影矩阵 $\mathbf{W}$ 投影到一个中间层中,输出的尺寸与embedding size相同,以便与尾实体表示 $\mathbf{e}_o$ 做内积, 获得相似度, 即Logits;
- 这种方式通过内积来比较所获向量与尾实体的相似度, 越相似得分越高.
- 然后将Logits经过 $\sigma$ 函数, 得到每个实体的概率: $$p=\sigma(\psi_r\left(\mathbf{e}_s, \mathbf{e}_o \right))$$
优化时的损失函数采用BCE(binary cross-entropy loss):
$$\mathcal{L}(p, t)=-\frac{1}{N} \sum_i\left(t_i \cdot \log \left(p_i \right)+\left(1-t_i \right) \cdot \log \left(1-p_i \right)\right)$$
$t$ 是尾实体的one-hot vector. 对于和输入的 $(s, r, ?)$ 匹配的位置为1,其余为0.
2.4.3 训练tips
2.4.3.1 基本tips
- rectified linear units: as the non-linearity $f$, 加快训练;
- batch normalization: after each layer to stabilise
- regularise: dropout
- optimiser: Adam
- label smoothing: to lessen overfitting due to saturation of output non-linearities at the labels
2.4.3.2 加速评估tips
卷积操作消耗大量时间
convolution consumes about 75-90% of the total computation time, thus it is important to minimise the number of convolution operations to speed up computation
思路1:增加batch size加速,但是CNN会使得GPU的内存超过限制;
解决办法:1-N scoring
ConvE最后的输出, 能获得对所有实体相关的Logits, 这样就能对所有的尾实体同时打分, 而不用考虑采样的问题. 在原文中这种打分方式被称为1-N Scoring.
过去评估时,需要采样负样本,进行1-1评估。现在这种方式能极大地加快Evaluation的速度, 因为负采样只能对单一的三元组打分, 而这种方式能同时对所有的尾实体同时打分。这种思想能够应用于所有的1-1 scoring Model.
这种方式其实本质上利用GPU并行执行的特点,在架构上将训练和评估同时考虑,通过将平衡计算性能和收敛速度,来使得评估过程加快。
3. 实验评估
3.1 数据集
| 数据集 | 来源 | 关系 | 实体 | 三元组 | 说明 |
|---|---|---|---|---|---|
| WN18 | a subset of WordNet | 18 | 40943 | 151442 | consist of hyponym and hypernym relations and, for such a reason, WN18 tends to follow a strictly hierarchical structure. 用WN18RR替代。 |
| FB15k | a subset of Freebase | 1345 | 14951 | —— | A large fraction of content in this knowledge graph describes facts about movies, actors, awards, sports, and sport teams. 用FB15k-237替代。 |
| YAGO3-10 | a subset of YAGO3 | 37 | 123182 | entities which have a minimum of 10 relations each | Most of the triples deal with descriptive attributes of people, such as citizenship, gender, and profession. |
| Countries | a benchmark dataset that is useful to evaluate a model’s ability to learn long-range dependencies between entities and relations. It consists of three sub-tasks which increase in difficulty in a step-wise fashion, where the minimum pathlength to find a solution increases from 2 to 4. |
3.2 超参
选择方法:
grid searchaccording to themean reciprocal rank (MRR)on the validation set选定范围:
embedding dropout: 0.0, 0.1, 0.2feature map dropout: 0.0, 0.1, 0.2, 0.3projection layer dropout: 0.0, 0.1, 0.3, 0.5embedding size: 100, 200batch size: 64, 128, 256learning rate: 0.001, 0.003label smoothing: 0.0, 0.1, 0.2, 0.3
最佳参数:
- WN18, YAGO3-10 and FB15k
embedding dropout: 0.2feature map dropout: 0.2projection layer dropout: 0.3embedding size: 200batch size: 128learning rate: 0.001label smoothing: 0.1
- Countries dataset
embedding dropout: 0.3hidden dropout: 0.5label smoothing: 0
early stoppingaccording to themean reciprocal rank(WN18, FB15k, YAGO3-10) andAUC-PR(Countries) statistics on the validation set
- WN18, YAGO3-10 and FB15k
3.3 结果
实验中进行评估时,有几件注意事项:
由于数据出现leakage,因此使用了rule-based method来识别逆向关系作为对照,同时在数据集包括有无逆向关系)中进行评估;
使用了
filtered setting;Rank test triples against all other candidate triples not appearing in the training, validation, or test set.
Candidates are obtained by permuting either the subject or the object of a test triple with all entities in the knowledge graph.
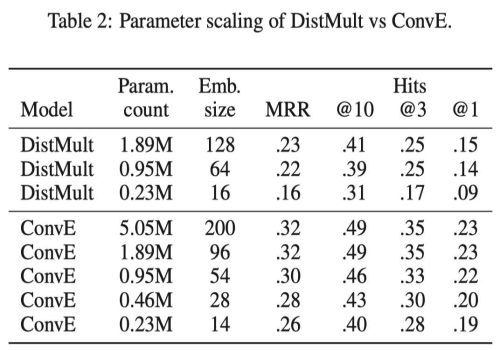
3.3.1 从参数效率看
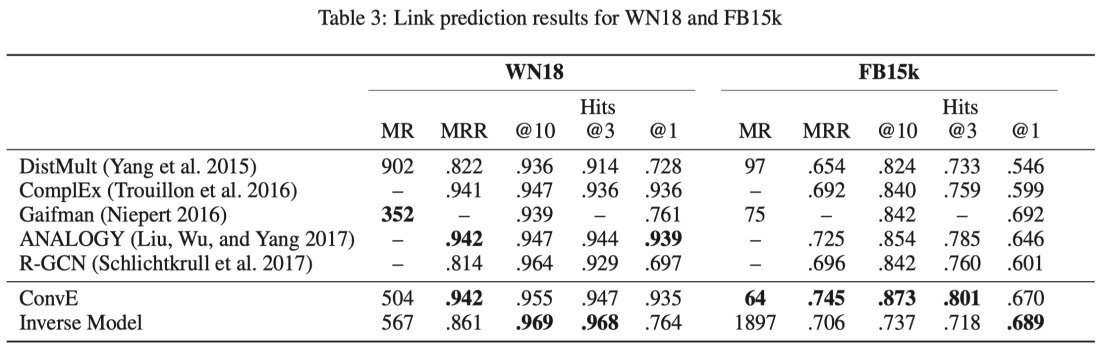
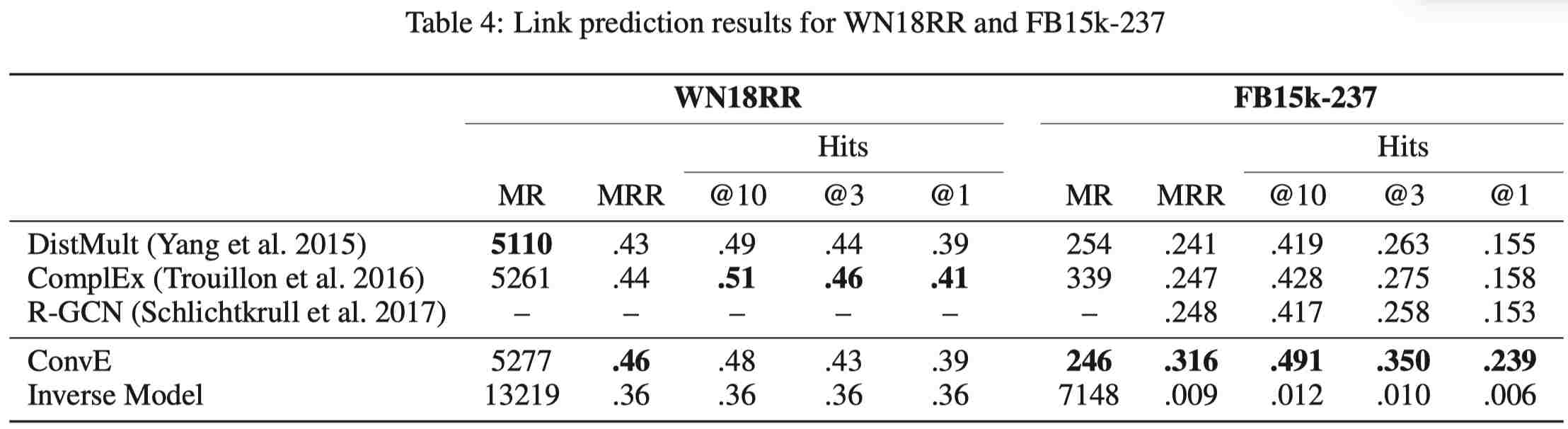
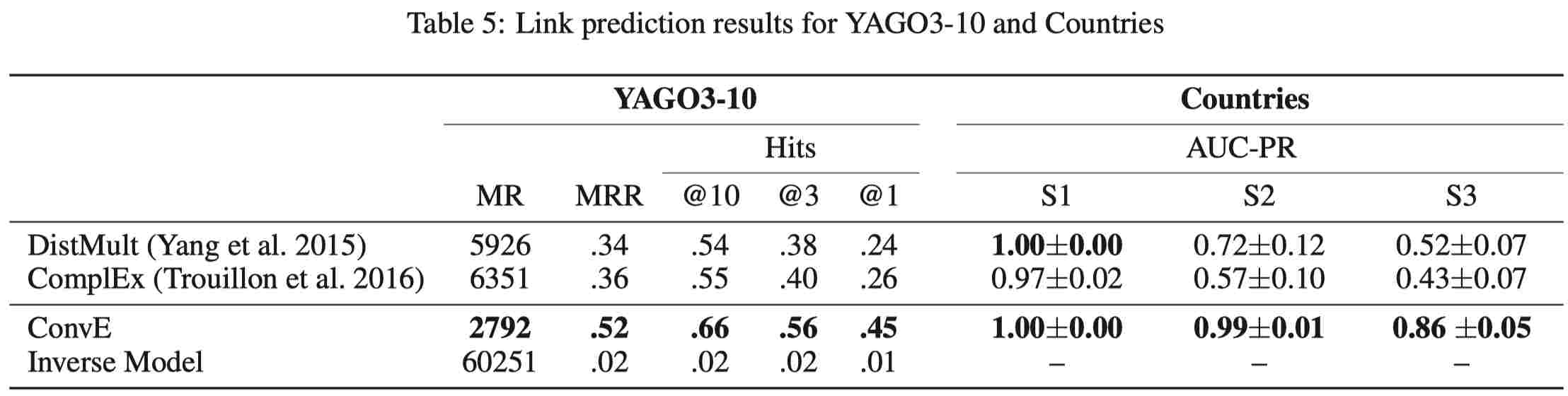
3.3.2 结果(含有逆向关系)
3.3.3 结果(不含逆向关系)
这里将数据集中存在逆向关系的三元组全部删除了,来避免leakage造成的负面影响。
3.4 分析
3.4.1 消融实验
为了查看,哪部分组件在整个架构中的作用最重要,消融实验显示:
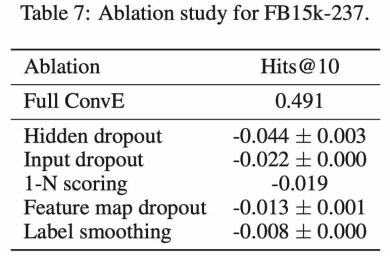
- hidden dropout的影响最大;
- 但是label smoothing的影响几乎可以忽略;
3.4.2 从图的结构分析优点
3.4.2.1 假设1
datasets contain nodes with very high relation-specific indegree时,ConvE效果更好,而indegree较小时,一些模型足以应对DistMult。
Our hypothesis is that deeper models, that is, models that learn multiple layers of features, like ConvE, have an advantage over shallow models, like DistMult, to capture all these constraints.
- 验证:通过将数据中indegree中的过大或者过小的node删除,然后分别使用ConvE和DistMult进行实验,验证了上述假设。
3.4.2.2 假设2
平均PageRank越高的graph,ConvE的性能相比于DistMult越好;
This gives additional evidence that models that are deeper have an advantage when modelling nodes with high (recursive) indegree.
- 验证:通过计算各个数据集的平均pagerank值,然后计算pagerank值与(convE - DistMult)差值计算相关性,验证了上述假设,这个假设2与假设1其实可以看成等价。
4. 代码实现
5. 问题
- 与CV中CNN的应用对比,模型仍是浅层,未来会增加深度的卷积模型。
- 2D卷积的解释;
- 如何更多地捕捉embedding之间的交互,例如通过增加大型结构;