前提假设
Open World Assumption(OWA)
开放世界假设,其含义在于暗含的假定为是未知的事实而不是假的,这也是“开放”这个词的含义,这么理解起来有点抽象,一个例子:宇宙内有除了人类的外星人,这个描述在Open World Assumption条件下,不是假的,你只能说它是未知的,这个问题的答案是“开放”的。
Closed World Assumption(CWA)
封闭世界假设,与开放对立,即:所有未知的都是假的。同样上述的例子:宇宙内有除了人类的外星人,这个描述在Closed World Assumption条件下,我们均认为它是错误的。
Local Closed World Assumption(LCWA)
这个是什么意思呢?与Closed World Assumption相关,这涉及到局部的情况。同样上述的例子:宇宙内有除了人类的外星人,比如:对于不同的人类,这个描述在Local Closed World Assumption条件下,不同的人可能有不同的回答,对于NASA或者国家航天局来说,他们可能知道但是不说,因此他们对这个的回答可能是正确的,而对于我们来说,一般来说是错误的,因为你肯定不知道。这种情况导致不同的人群对于同样的问题出现认知的不同,所以Closed World Assumption假设过于绝对了,因此引入了Local Closed World Assumption,即:对于所有未知的知识中的一部分认为是错误的(因为有人认为那是对的)。
Stochastic Local Closed World Assumption(sLCWA)
这个假设,是在Local Closed World Assumption基础之上构建的。其实这个词相比于上述三者使用的较少,它需要和具体的采样策略结合来看。因为人类的知识没有办法具体的统计出来,因此日常接触到的知识均可以视为Local Knowledge, 而基于Local Closed World Assumption,所有不属于Local Knowledge的知识都是错误的。Stochastic Local Closed World Assumption则告诉我们,如果在这些“错误”的知识中进行采样,来帮助训练。
不同假设对于训练的影响
这种假设条件对于知识图谱嵌入的影响如下:
| Assumptions | 影响 | 采用情况 | 说明 |
|---|---|---|---|
| Open World Assumption | 会导致欠拟合under-fitting,也即over-generalization) | 一般不用 | 直观理解,当一个模型对于一个自己认知之外事务,不明确表达态度时,其实是一种“缺乏自信”的表现,也会对所有已知和未知的事务同样保持“中庸”。 |
| Closed World Assumption | 会导致over-fitting,即泛化程度很低 | 一般不用 | 这种假设太过绝对,只要我不知道,就是错误的,有点过于“自负”,这种模型除了自己知道的事务,对其他均不认可。 |
| Local Closed World Assumption | 根据已有的知识,生成一部分“假”知识 | 可用 | |
| Stochastic Local Closed World Assumption | 根据已有的知识,生成一部分“假”知识,从这些假知识中进行采样 | 可用 |
如何生成“假”知识?
问题定义
来自于 source。
Throughout the following explanations of training loops, we will assume the set of entities $\mathcal{E}$ , set of relations $\mathcal{R}$ , set of possible triples $\mathcal{T} = \mathcal{E} \times \mathcal{R} \times \mathcal{E}$. We stratify $\mathcal{T}$ into the disjoint union of positive triples $\mathcal{T^{+}} \subseteq \mathcal{T}$ and negative triples $\mathcal{T^{-}} \subseteq \mathcal{T}$ such that $\mathcal{T^{+}} \cap \mathcal{T^{-}} = \emptyset$ and $\mathcal{T^{+}} \cup \mathcal{T^{-}} = \mathcal{T}$ .
“朴素”的方法
对于一个已有的知识图谱而言,根据Closed World Assumption,任何不在该知识图谱内的知识或者三元组都是假知识。
一种“朴素”的负样本的生成办法是:
对于三元组,可能的组合有以下几种:
- N(head): 代表head实体的种类数量;
- N(rel): 代表relation的种类数量;
- N(tail):代表tail实体的种类数量;
则可能的三元组的数量为:
$$
N(head) \times N(rel) \times N(tail)
$$
当删除知识图谱内的三元组时,就可以认为是所有的负样本。这种负样本的数量是巨大的。
一种可以解决方法是:采样。具体的采样方法有很多种,这里不赘述了。
但是有一种情况,我们的模型需要更容易地对真知识进行判断,举个例子:
对比,高圆圆比娜扎漂亮,我们假设它是对的,当出现凤姐时,模型已经认识高圆圆,它能得出高圆圆比凤姐漂亮。但是当得到的负样本为:梅根福克斯与克劳馥时,你觉得模型对:
- 高圆圆与凤姐
- 梅根福克斯与克劳馥
哪个容易判断。
LCWA下的负样本生成
基于上述的情况,在Local Closed World Assumption下,负样本的生成基于以下原则:任意替换三元组的任意一个位置,得到的负样本不属于知识图谱本身,即认为是负样本。
根据这个原则,可以有三种类型的操作:
head generation: $(h, r, t)$ -> $(h, r, t_i)$;
In this setting, for any triple $(h, r, t) \in \mathcal{K}$ that has been observed, a set
$\mathcal{T^{-}} (h, r) $ of negative examples is created by considering all triples $(h, r, t_i) \notin \mathcal{K}$ as false.relation generation: $(h, r, t)$ -> $(h, r_i, t)$;
In this setting, for any triple $(h, r, t) \in \mathcal{K}$ that has been observed, a set
$\mathcal{T^{-}} (h, t) $ of negative examples is created by considering all triples $(h, r_i, t) \notin \mathcal{K}$ as false.tail generation: $(h, r, t)$ -> $(h_i, r, t)$;
In this setting, for any triple $(h, r, t) \in \mathcal{K}$ that has been observed, a set
$\mathcal{T^{-}} (r, t) $ of negative examples is created by considering all triples $(h_i, r, t) \notin \mathcal{K}$ as false.
一般情况下,在Local Closed World Assumption下,很多的实现都只会考虑head generation和relation generation,不会考虑tail generation。
sLCWA下的负样本生成
从Local Closed World Assumption中的三种情况下进行的集合进行采样,即:
- $(h, r, t)$ -> $(h, r, t_i)$
- $(h, r, t)$ -> $(h, r_i, t)$
- $(h, r, t)$ -> $(h_i, r, t)$
但从实际来看,有时候只需要$(h, r, t)$ -> $(h, r, t_i)$和$(h, r, t)$ -> $(h_i, r, t)$,而没有考虑关系的替换,然后从这两者的集合中进行采样。
| Assumptions | Local Closed World Assumption | Stochastic Local Closed World Assumption |
|---|---|---|
| 负样本来源 | $(h, r, t)$ -> $(h, r, t_i)$, $(h, r, t)$ -> $(h, r_i, t)$ | $(h, r, t)$ -> $(h, r, t_i)$,$(h, r, t)$ -> $(h_i, r, t)$ |
| 是否要采样 | 不需要 | 需要 |
| 过滤正样本 | 需要 | 需要 |
例子说明
这个具体的帮助理解的例子来自于:
Bringing Light Into the Dark: A Large-scale Evaluation of Knowledge Graph Embedding Models Under a Unified Framework
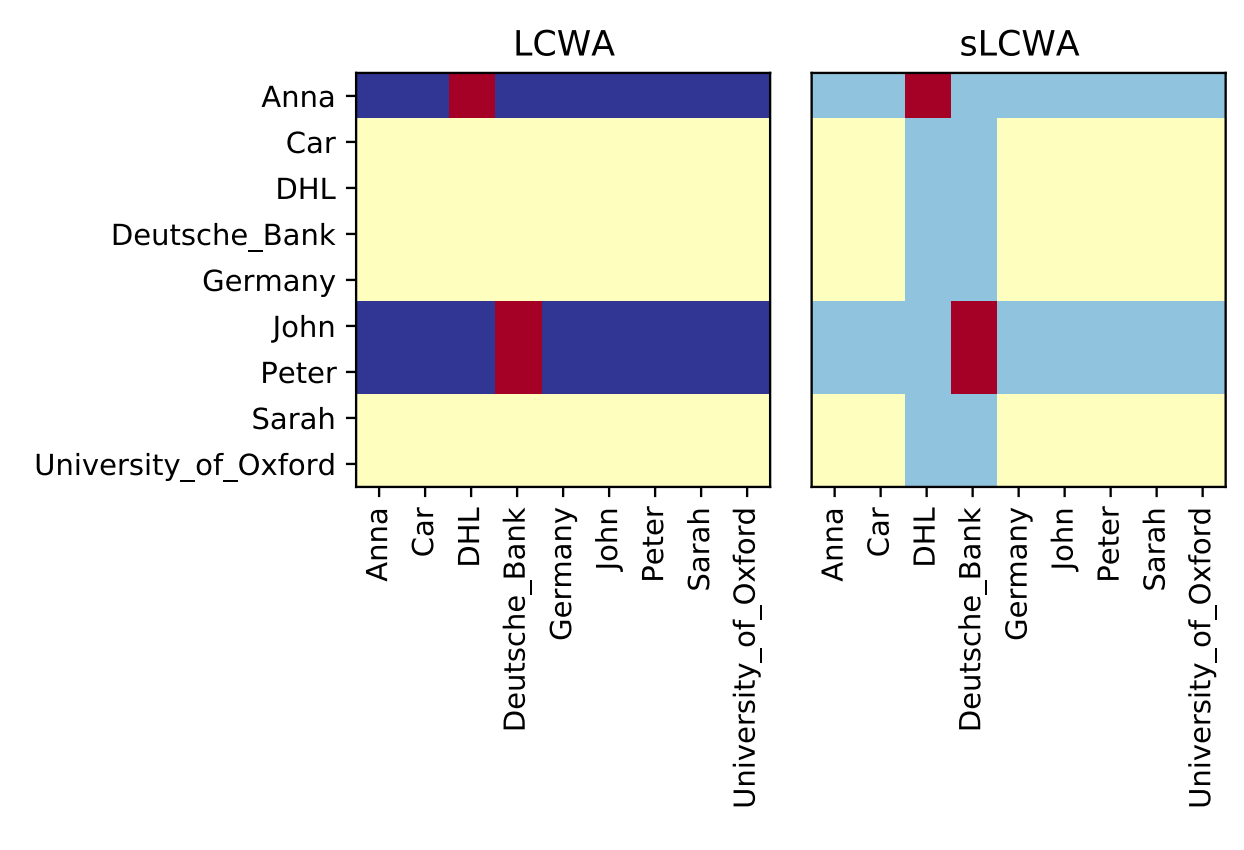
该图对比了负样本在:
- Local Closed World Assumption
- Stochastic Local Closed World Assumption
两种生成策略。
对于同一种关系 works_at, 红色部分是true triples。
- 在LCWA生成的是深蓝色对应的负样本,它们都没在原始的知识图谱上。
- 在sLCWA生成的是浅蓝色对应的负样本,并从其中采样,它们都没在原始的知识图谱上。
- 黄色部分则不在负样本的考虑之列。

