在cache性能量化的文章中,提到使用平均访存时间在衡量cache的性能。由于miss cache是cache 访问的核心瓶颈之一,因此为了提升性能,可以通过有效减少miss rate来实现。
不同的miss类型
对于造成cache出现miss的原因有很多,根据这些原因,可以将miss的类型分为3类:
- Compulsory misses/cold-start misses
- 即,第一次访问main memory中的一个block,该block从未在cache中出现过;
- 典型的场景:在计算机开机后,很多的程序还未运行,只能从main memory中加载数据,这种场景的cold-start miss很难避免;
- 这种miss,可以通过增加cache line中block 的size,从而利用空间局部性,使得一些数据在没有访问时也会被加载到cache中,但是这种方法会增加miss penalty,因为block增加,从main memory读数据的时间就会增加。
- Capacity misses
- 由于cache容量有限,导致无法容纳所有来自main memory的内存,造成了miss;
- 典型场景:block被放到cache中,但是还未查询hit,就被替换了;
- conflict misses/collision misses
- 来自main memory不同地址的多个block竞争cache中的同一个位置;
问题描述
那么如何减少miss rate呢?首先要明白miss产生的具体场景都有哪些:
- cache的空间不够:导致只能存储部分来自内存的数据,这样很多数据无法进入cache,导致出现miss;
- 来自多个main memory的数据竞争cache line:导致cache中的数据被频繁替换,刚进入cache中的数据还未被hit,就被替换,从而导致miss;
这两种问题,其实可以通过扩大cache的容量来解决,但是扩大cache容量带来两个负面影响:
hit time会增加,根据平均访存时间的公式,这也会影响性能;- 成本增加;
那有没有一个方法,可以在不改变cache容量的前提下,能够提高cache的性能?这里要解决的一个关键问题是——如何解决来自内存中的数据在cache中频繁发生的替换问题?
那么为什么会有频繁替代呢?简单来讲,僧多肉少。
main memory中的每个地址中的数据在cache中只有一个位置,即存在一对一的映射关系,但是一个cache line对内存中的数据则由一对多的映射关系。因此,多个内存中的数据竞争一个位置,当然会有频繁的替代了。
核心问题明确了,为了减轻竞争,我们要将之前的main memory中的地址与cache line一对一的关系,改为一对二,甚至一对三,这样就不会有激烈的竞争。实现这种策略的方法是——set associative。
两个极端的方案
direct mapped cache
到目前为止,之前提到的所有的cache的placement scheme均为direct mapped,简单讲,一个来自内存的block只能对应一个cache line,这个映射关系由main memory的地址决定。
但是对于cache中各种line的组织方式不仅仅这一种placement schema。这种方式只是一种极端的方式。
fully associative
相比于direct mapped cache,这种策略走到了另一个极端,非但不将内存中的数据映射到cache中一个位置,而是映射到任意的位置。
这种方式的好处是,将不同内存地址之间的冲突最大程度上缓解了,当direct mapped中两个内存地址映射到相同的cache line导致被替换时,在fully associative中只是简单的换一个位置即可。
有好处,就会有代价。当在cache中搜索时,就不如direct mapped策略中那么方便了,在direct mapped中,只要比较了index和tag就可以确定block,但是在fully associative中,必须比较block中各个words的地址,甚至byte offset(words中字节的偏移地址)。这种比较给硬件带来了极大的性能负担,为了在实际中应用,一般上述的比较过程都是并行的,即便如此,这种策略也只是在小容量的cache中使用。
折中方案——set associative
基本原理
上述两个方案均走了极端,一个是只映射到一个位置,一个是可以映射到任意位置。权衡之下,set associative只映射到n个位置。
在set associative,来自内存的数据可以随意映射到n个位置,这种策略称为n-way set-associative cache。
- 其中包含一系列的
sets,每个set中包含n个位置; $$
\text{The number of sets} \times n = \text{The number of cache lines}
$$ - 每个来自内存的block可以映射到唯一的set; 不同于direct mapped cache,寻找对应的set,通过如下方式: $$
\text{(block number) modulo (number of sets)}
$$ - 这个block可以放到所映射的唯一的set的任意位置;
这种策略融合了direct mapped和fully associative的优点:
- direct mapped的快速寻找:block只能映射到唯一的set中;
- fully associative的缓解cache line竞争:在唯一的set中可以随意放置;
三种策略对比
针对如下的例子进行对比,对于一个block address为12的block,如何在上述3种策略中放置:
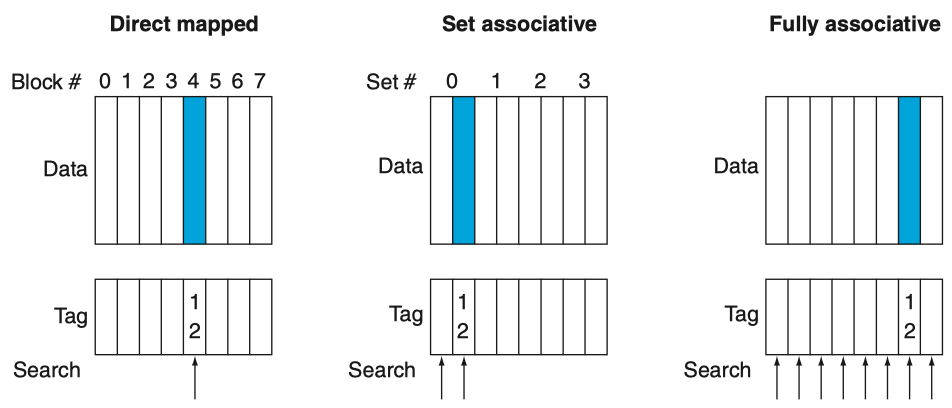
- direct mapped中,12 % 8 = 4,只能映射到一个位置,但是搜索该位置只需要1次;
- 2-set associative中,12 % 4 = 0,即只能映射到index=0的set,但是可以在其中的2个位置,任选一个,因此需要搜索两次;
- fully associative中,12对应的block可以映射到任意位置,但是要对所有的cache lines进行搜索;
综上,
- direct mapped可以看作 1-set associative,只能映射到一个位置,是一种特例;
- fully associative可以看作m-set associative,可以映射到m个位置,其中共有m个cache lines,也是一种特例;

这里有一个associativity的概念,本质就是一个set中有几个cache lines。
对比3种策略,随着associativity的不断增加,也即set数量的不断减少(相同数量cache lines的情况下),cache的miss rate是不断下降的。
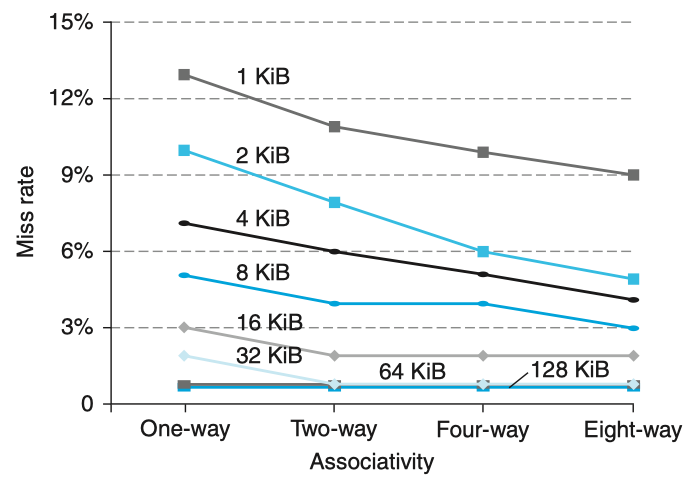
但是,随着cache size的不断增大(图中的不同折线),associativity的不断增加,所起到的作用不再明显,甚至微乎其微。
当然,associativity增加也会带来副作用,比如增加搜索的成本,同时hit time也会增加(因为搜索空间变大了嘛)。
定位set associative中的block
我们在之前的文章里,描述过如何将内存中的数据映射direct mapped cache中。现在placement schema变化了,那么这种映射方式如何变化呢?与direct mapped类似。
- 在set associative cache的line中,也存在tag字段,对应内存的高位地址;
- index字段也存在,不过不是用来索引lines,而是索引映射的set;
- block offset:用来寻址block内部的数据,作为偏移量;
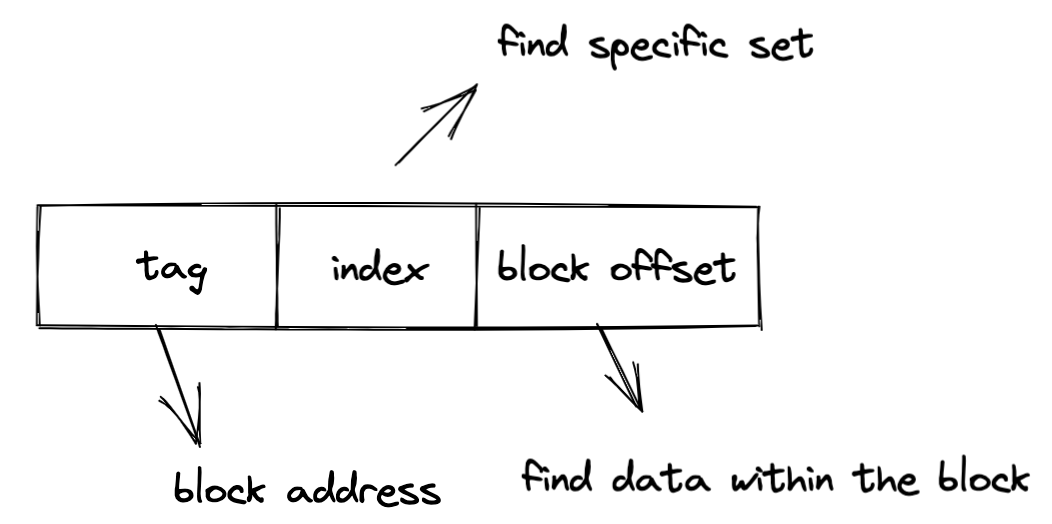
与direct mapped cache中不同的是,虽然有唯一映射的set,但是在该set中,可以随意放置block,因此搜索是一个问题,如果一个一个的串行搜索导致hit time大幅提升,因此实际中一般是并行搜索。并行的速度受到sets数量的影响,当同样数量的cache lines时,sets数量越多,并行搜索的效率越高。
下例中,为了实现一个4-set associative cache,执行并行搜索需要的电路结构。
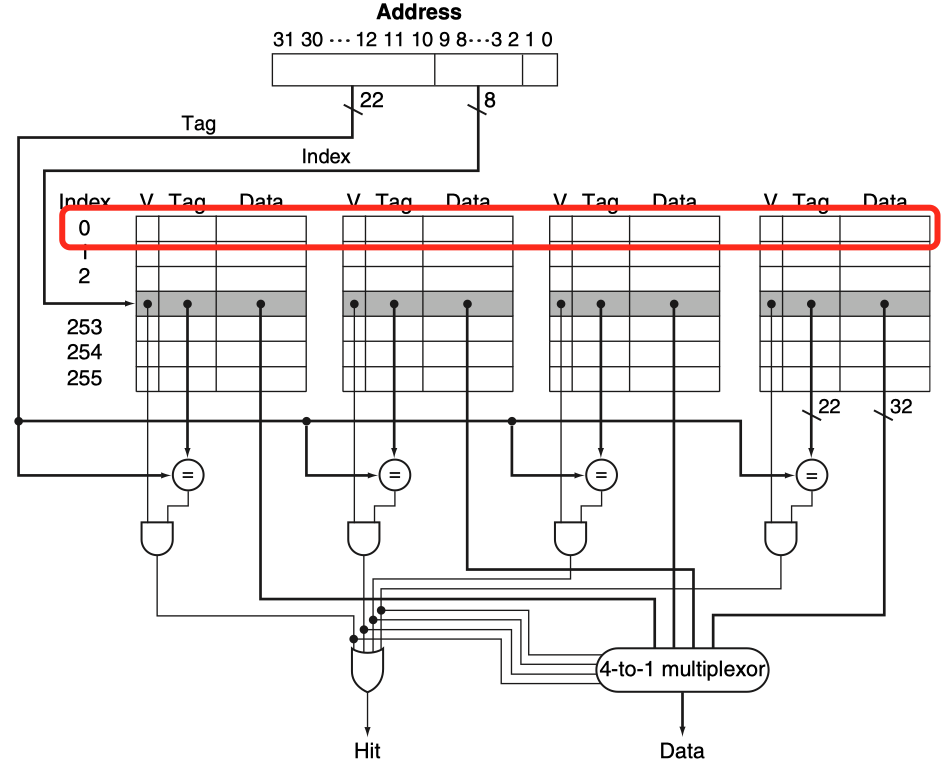
图中标红的部分是由4个block组成的一个set,共有256个set。
总结来看,3种placement schema的block定位方法如下:
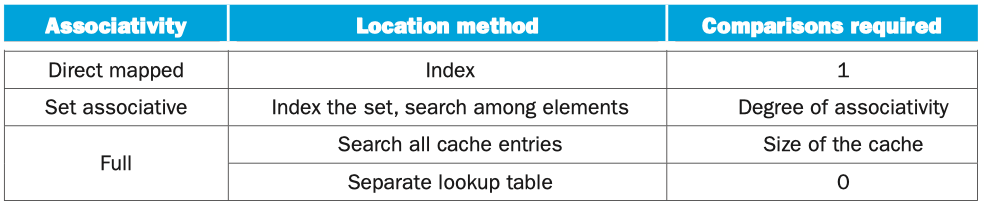
考虑到miss rate带来的影响,以及实现set-associative需要付出的时间和额外硬件的成本,选择哪种placement schema还要具体问题具体分析。
如何选择需要替换的block
在set associative中出现一个新问题,选哪个block被替换?在direct mapped cache中不存在这个问题,因此是一对一的,新的替换旧的,如此简单。
但是,在set associative和fully associative中,因此在一个set中可以随意选择放置位置,因此需要决定当set中的block满了时候,如何替换?此时,一般有如下的几种策略。
Random
- 对于替换set中的哪个block,不是确定的,而是每次随机;
- 一般使用一些硬件电路实现,实现简单;
Round-Robin
- 按照预先设定的顺序依次选择Cache块替换;
- 硬件简单,性能一般;
LRU (Least recently used)
- 选择距离现在最长时间未被访问的Cache块替换,因为这些block已经不符合时间局部性了;
- 在实践中,通过记录该set中每个block相对于其他block的使用次数,来决定被访问次数最少得block。
- 一般通过硬件实现替换算法,这个操作成本很高,一般只在4-set associative以下使用;
所谓性能优化,肯定是牺牲了一些,得到另一些,需要权衡。
- 表现较好,但是硬件电路复杂;
- 由于LRU在复杂的set associative中实现复杂,一般都是近似记录,而且这种实现在一些场景中没有比随机替换好;
总结
对于cache中miss问题的解决,不能只从一个角度考虑,因为各种因素之间是互相影响的,回到开篇提到的3种miss,不同策略优点和缺点如下:

set associative虽然能减小miss rate,但是会增加hit time,也会增加电路结构的复杂性,因此实际应用时,需要根据具体问题具体分析。
参考资料
- Computer Organization and Design - 5.4.1 - 5.4.3
- Computer Organization and Design - 5.8

