数据共享的需求和问题
在多线程的程序中,不同的线程之间存在数据共享的需求,但是在数据共享的时候,存在一些问题:
- 多个线程共享数据时,最后数据的状态由哪个线程决定;
- 多个线程同时写的时候,哪个线程先写;
数据在多个线程之间共享时,对其的读操作基本不会产生问题,但是一旦有任何一个写操作,都会产生问题,因此需要规范不同线程对于共享数据的访问。
不同线程对于共享数据的修改,导致了数据最终状态的不确定,其最终的状态取决于这些线程之间的执行顺序,这种情况被称为条件竞争,race condition。
A race condition is an undesirable situation that occurs when a device or system attempts to perform two or more operations at the same time, but because of the nature of the device or system, the operations must be done in the proper sequence to be done correctly.
这种情况出现的原因在于对于invariants的破坏,不同的线程同时访问一个共享的数据,当线程B访问数据时,以为该数据是自己访问之前看到的样子,但是实际上已经被线程A修改了,导致出现预期之外的结果。
多个线程对于invariants的访问一定会产生race conditino吗?不一定,需要明确这些线程的目的是什么,比如生产者和消费者模型中,不同的生产者都向任务队列中提交任务,它们不考虑队列里有什么,这也是一个写操作,但是任务和任务之间假设没有依赖关系时,则不是race condition。
条件竞争的解决
race condition肯定是我们极力要避免的,我们有几种办法来解决它:
保护共享数据
确保任意时刻只有一个线程能够访问该共享数据的中间状态,其他线程只能看到数据的原始状态或者被修改线程的最终状态,这样保证了不同线程读到的数据都是确定的,不会在其他线程修改后,还会读到原始数据。
这种方式在C++中一般是通过互斥量实现的。
无锁编程
无锁编程的基础是原子操作,这依赖于硬件的支持。更多的资料可以参考:
使用事务
类似于数据库的事务,来处理数据的更新,这里使用称为software transactional memory的技术。
使用互斥量解决条件竞争
所谓互斥量,通俗的理解,是多个线程访问共享的数据时,任何一个线程在修改数据时,其他的线程都必须等待。
基本使用方式
在一个线程访问共享数据前,先将数据锁住,在访问结束后,再将数据解锁。当访问线程使用互斥量锁住共享数据时,其他线程都必须等到该线程对数据解锁后,才能进行访问该数据。
在C++中通过std::mutex实现互斥量,基本使用如下:
#inlcude <mutex>
mutex thread_mutex;
int global_i = 10;
void do_on_background(int i){
thread_mutex.lock();
cout << "thread id: " << this_thread::get_id() << endl;
global_i += i;
cout << "gobal_i is : " << global_i << endl;
thread_mutex.unlock();
}
int main(){
int a = 100;
thread t1(do_on_background, a);
int b = 200;
thread t2(do_on_background, b);
t1.join();
t2.join();
}
这里的输出虽然也是不确定的,但是输出中,global_i可以为110/310,或者210/310,这是因为两个线程t1和t2被调度的先后顺序可能不同。但是因为这里两个线程对象的join都在最后,两个线程之间没有顺序,所以才会出现输出有两种可能。
上述的基本使用方式,每次都需要用lock和unlock成对使用,而且因为异常的原因,如果抛出的异常没有被捕捉,则会导致失败。修改函数do_on_background如下:
void do_on_background(int i){
thread_mutex.lock();
cout << "thread id: " << this_thread::get_id() << endl;
global_i += i;
cout << "gobal_i is : " << global_i << endl;
throw invalid_argument("invalid argument");
thread_mutex.unlock();
}
当发生异常时,只会执行一个线程,输出的结果只可能是110或者210,不能有两个,因为当异常抛出时,导致没有执行到unlock就直接终止了,另外的线程也就不会进入共享数据中。
当异常被捕捉后,就可以正常解锁,可以让两个线程都访问到共享数据。
void do_on_background(int i){
thread_mutex.lock();
cout << "thread id: " << this_thread::get_id() << endl;
global_i += i;
cout << "gobal_i is : " << global_i << endl;
try{
throw invalid_argument("invalid argument");
}
catch(const exception &e) {
cout << e.what() << endl;
thread_mutex.unlock();
}
thread_mutex.unlock();
}
但是这种lock和unlcok的方式很繁琐,还要考虑异常的情况,使用RAII的方式可以优雅地解决这个问题。
RAII的方式:使用lock_guard
C++支持使用RAII的方式使用互斥量——通过std::lock_guard实现。构造时提供已锁的互斥量,并在析构时进行解锁,从而保证了互斥量能被正确解锁。使用如下,只需要修改do_on_background函数即可:
void do_on_background(int i){
lock_guard<mutex> guard(thread_mutex);
cout << "thread id: " << this_thread::get_id() << endl;
global_i += i;
cout << "gobal_i is : " << global_i << endl;
// throw invalid_argument("invalid argument");
}
这里当函数中抛出了异常,没有被捕捉,仍然会直接终止,最终只有一个线程被执行。
上述例子中都是针对全局变量的,实际开发中,互斥量多是与要保护的数据放到一个类中,可以对类进行封装,提供数据保护。
漏洞:来自指针和引用的隐秘操作
互斥量并不是万无一失的,还是需要仔细梳理代码逻辑来保证正确,将对类的数据访问全部限制在互斥量的范围中才能较好的保护数据。当对数据的访问和修改脱离了互斥量的作用范围,就很容易产生问题,这种情况的典型例子是指针和引用,因为能够直接操作数据,所以更加危险。
class raw_data{
private:
int a;
public:
void do_something(){
a = 100;
cout << "a = " << a << endl;
}
};
class data_wrapper{
private:
raw_data data;
mutex m;
public:
template <typename Function>
void process_data(Function func){
std::lock_guard<std::mutex> guard(m);
func(data);
}
};
raw_data *unprotected;
void malicious_function(raw_data &protected_data) {
unprotected = &protected_data;
}
int main()
{
data_wrapper x;
x.process_data(malicious_function);
unprotected->do_something();
}
/** output
a = 100
*/
即便在类data_wrapper内对于数据的访问在互斥量范围内,但是由于访问数据之后,导致返回了引用类型,导致类的外部可以通过raw_data对象的指针修改累的数据,这已经超过了互斥量作用的范围。
基于这种问题,需要注意:
- 不要将类中数据的指针或者引用传递到类外,脱离互斥量的管控;
- 不要将外部不在互斥量影响范围内的函数传递到类中;
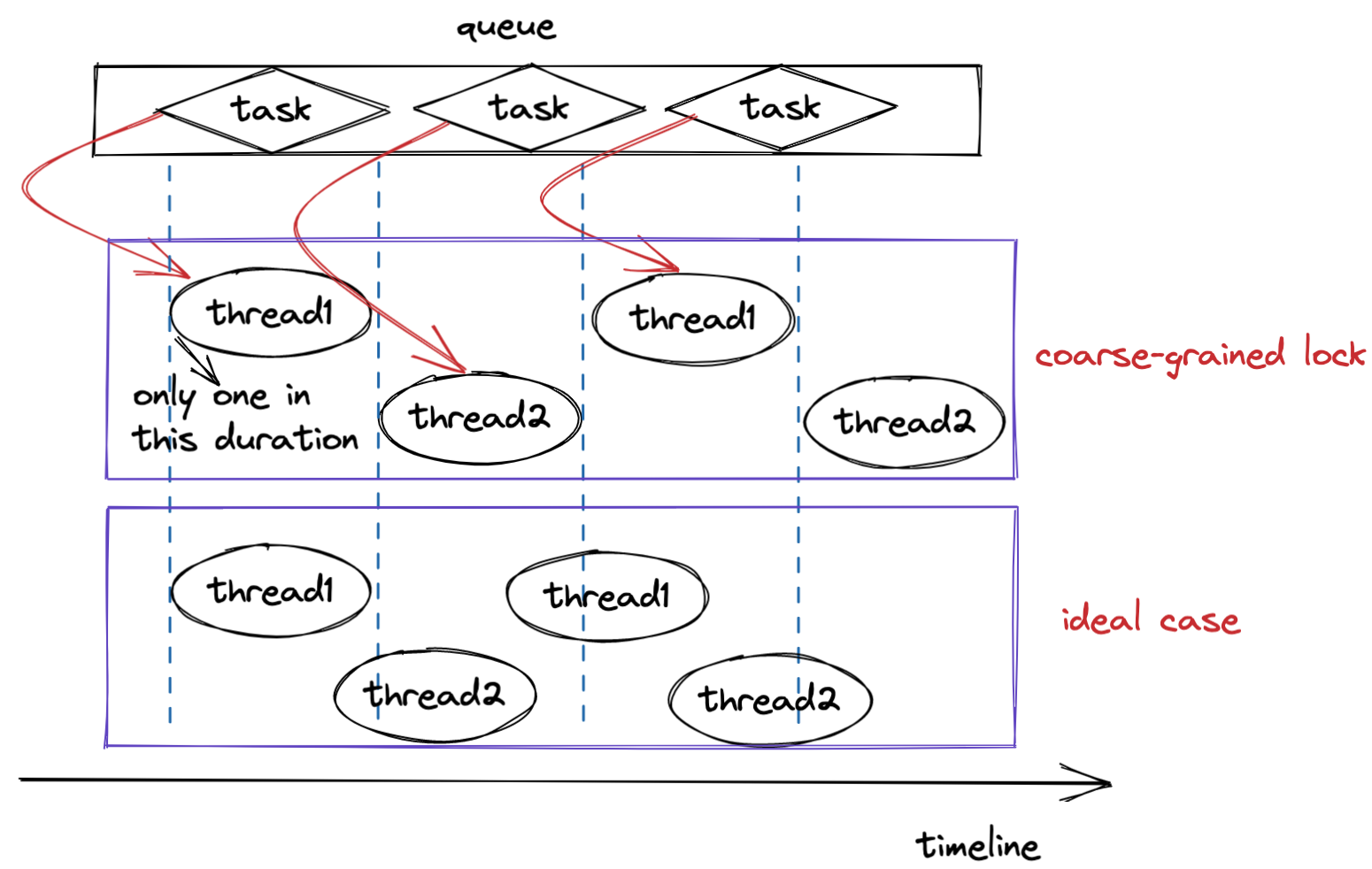
锁的粒度导致的问题
在上述的说明中,当需要对多线程访问共享数据进行保护时,需要使用互斥量对于共享数据进行保护,使得只有一个线程能够操作。换言之,只要多线程操作数据,就让互斥量参与其中,就能确保万事大吉吗?显然不是这样,这涉及到锁的粒度的问题。
仍然存在条件竞争
当锁的粒度过细时,对于多种操作的组合,可能仍然存在race condition,怎么理解这句话呢?还是代码说话吧。
struct task
{
string name;
int priority;
task(string n, int p){
name = n;
priority = p;
}
};
class task_queue{
private:
mutex m;
deque<task> tasks;
public:
void add_task(task t){
lock_guard<mutex> guard(m);
tasks.push_back(t);
}
task get_oldest_task(){
lock_guard<mutex> guard(m);
task oldest_task = tasks.front();
tasks.pop_front();
return oldest_task;
}
task front(){
lock_guard<mutex> guard(m);
return tasks.front();
}
void pop_front(){
lock_guard<mutex> guard(m);
tasks.pop_front();
}
};
void process_task(task_queue &tq){
// method 1. not safe
// task t = tq.front();
// this_thread::sleep_for(chrono::milliseconds(1));
// tq.pop_front();
// method 2. safe
task t = tq.get_oldest_task();
cout << "process task : name = " << t.name << "; priority = " << t.priority << endl;
}
int main(){
task_queue tq;
tq.add_task(task("task1", 1));
tq.add_task(task("task2", 2));
tq.add_task(task("task3", 3));
thread t1(process_task, ref(tq));
thread t2(process_task, ref(tq));
t1.join();
t2.join();
return 0;
}
这里,我们构建一个task_queue,其中每个操作都在lock_guard的保护之下,但是在使用process_task时,使用method 1时,发现task1被处理了两次,而且一个task丢失了,没有被处理。这里使用两个线程去处理,因为计算机太快,可能运行很多次也不会有错误的输出,因此这里稍微sleep一下,现象就比较明显,如下:

上述中,打印输出因为没有同步,也会出现乱序,是可以预期的。当使用method 2时,就不会出现上述行为,其原因在于,两种情况下,lock_guard保护的范围不同,如下分析:
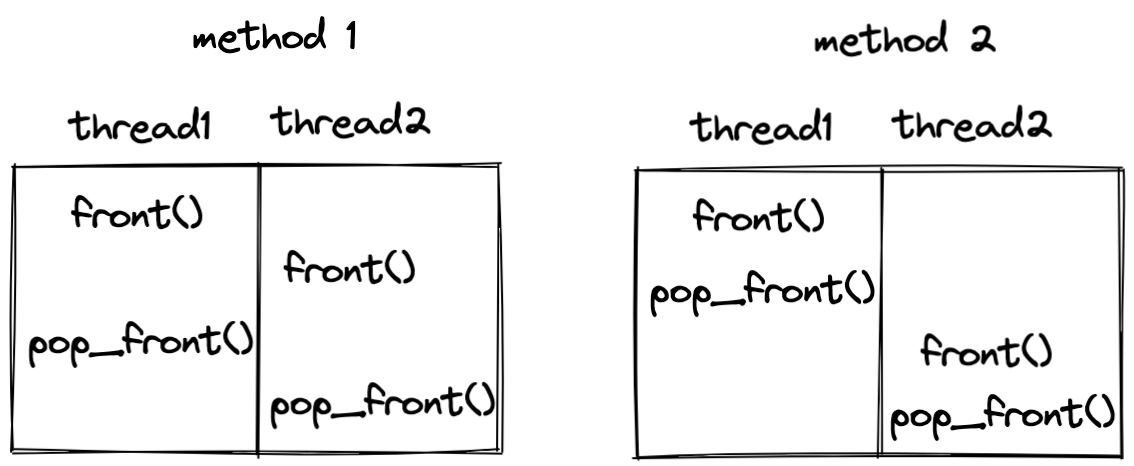
因为锁的粒度不同,在方法一种,任何时刻,保证了只有一个线程能够访问对应的操作函数,但是不能保证两个函数都在一个被保护的范围内,这就出现了交叉,也就出现了race condition;当两个操作被一个lock_guard保护时,就不会出现交叉的问题。
性能太差
基于上述的分析,粒度过小时会出现同步的问题,那将粒度很大时,保护范围就大了,就不会出问题了。这个说法从共享同步的角度说得通,但是此时使用多线程的技术就没有什么意义了,这是因为,当锁的粒度太大时,并行就会变成串行,严重影响性能。而在实际情况中,这种多线程退化为单线程的方式,其实比单线程性能更低,因为还有线程切换消耗的资源。